星级评价:
日期:09-04
立即下载
XPath2Doc 是一个半自动采集网页生成Word docx文件的工具,带企查查、天眼查采集配置,使用XPath2Doc需要自己在WebBrowser窗口里面手工登录,并找到需要的数据页面,然后点击程序按钮进行采集,所以是个半自动的网页数据填充Docx工具。
网页的每个元素,都可以表示成为XPath语句,所以我们可以读取浏览器打开的网站页面源代码,通过XPath语句得到网页元素中的文本。
XPath语句的获取办法:
通常我们可以使用谷歌的Chrome浏览器打开网站页面,按F12调出开发者工具界面,在ELements选项卡下,随着鼠标的移动可以看到网页内容被阴影覆盖,点开三角符号,可以更进一步定位准确的位置,直到找到最终需要的数据位置。在找到的文本上点鼠标右键,在弹出的菜单中,选择Copy-Copy XPath,然后粘贴到记事本即可得到需要的XPath语句。
这里需要说明一点:如果拷贝出来的XPath语句中有/tbody会影响采集,程序内部对此问题进行了处理,但可能会在某些特殊情况下还是会影响数据采集,可以手工去掉。
1、本程序工作需要三个配置文件:General.ini,自定义.ini,自定义模板.docx。后两个文件名自己定义。
General.ini文件中定义了INI文件和Docx模板文件的存放目录,可以不填,默认是程序所在目录。
自定义.ini、自定义模板.docx是软件使用者自己创建的网页采集XPath语句及最后生成文件所用的Docx模板,具体设置方法请看ini文件中的说明。注意,Docx模板文件中的“@<#0001#>@”之类的字符是在INI文件中定义的用于替换网页采集内容的标记字符串。ini文件中定义了替换关键字的前后缀和模板文件名。
2、使用本程序前,请先建立好你自己的INI配置文件和Docx模板文件。(具体可以参见附带的企查查、天眼查两个配置文件和起诉书模板)
需要说明的是,模板文件支持对文档的不同部分使用不同的网址进行采集,注意Url的设置。
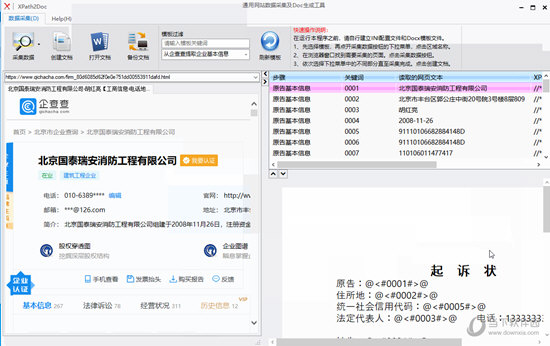
启动程序--选择模板--点击采集数据按钮旁边的黑色三角符号,点开下拉菜单,点击需要采集的部分。等候浏览器加载网页完毕,手工输入需要查询的内容,点击查询,找到数据的具体页面,然后点击采集数据按钮,观察右侧的列表中是不是已经得到需要的数据。继续点开下拉菜单,选择下一个需要采集的部分,如果网址发生了变化要等候浏览器加载完毕,找到需要的数据页面。点击采集数据按钮观察右侧列表中是不是得到了第二部分的数据。如此反复,直到数据全部采集完毕。
如果前后两部分的网址相同,在点击下一部分的下拉菜单之前,要先在浏览器中重新查询新的数据,等新数据页面出来之后在点击下拉菜单选择下一部分进行采集。(网址相同的情况下,点击下一部分会直接从网页取数据,如果浏览器没有换页面,数据就错了。)如果某个部分需要重新采集,请先点击下拉菜单中的该部分名称,然后点击采集按钮重复采集该部分(此时可以随意改变浏览器的数据页面,得到的就是不同公司数据)。
列表中采集得到的数据结果如果有偏差,可以单击自行修改。XPath语句如果有什么错误,也可以自己修改看测试结果(XPath语句在修改后会立即重新抓取浏览器的数据,所以浏览器最好是有效数据页面),在程序中修改的XPath语句,不会保存到INI文件中,请自行手工保存。
如果列表中数据无误,预览窗口中的Docx模板内容也正确,则可以点击创建文档按钮,填写要生成的文件名,本软件会使用抓取到的网页数据替换模板中的索引字符串,自动生成Docx文档。
需要说明的是,右下角的Docx预览窗口不能完整的支持Word文档,对不标准的文档可能会出现文本缺失或者错位现象。遇到这种情况,可以忽略,或者将模板文件改成规范的文本格式(单倍行距)。
其他版本
本类下载排名 总 月
EShare电脑版 V7.2.603 官方安装版
536次软件大小:14.54 MB
更新日期:2024-10-07
Dns Jumper(DNS切换工具) V2.2 便携版
291次软件大小:624.84 MB
更新日期:2024-10-12
诚达企业信息采集软件 V2.1 绿色版
247次软件大小:2.49 MB
更新日期:2024-10-13
fs2you下载器 V2.2.0.1绿色便携版
244次软件大小:3.63 MB
更新日期:2024-10-08
百度图片批量下载器 V9.0.3.3512 官方版
227次软件大小:9.97 MB
更新日期:2024-10-08
向日葵控制端 V5.0.0.29520 64位官方安装版
197次软件大小:8.24 MB
更新日期:2024-10-07
MTools(快速配置IP和DNS) V1.0 绿色版
188次软件大小:22.27 KB
更新日期:2024-10-13
WALTR PRO(苹果文件同步工具) V1.0.62 PC版
186次软件大小:42.03 MB
更新日期:2024-10-13
4K Stogram(Instagram视频下载)V3.0.7 多国语言安装版
185次软件大小:54.58 MB
更新日期:2024-10-13
圣道小米抢购软件 V5.0 绿色版
167次软件大小:1.23 MB
更新日期:2024-10-13
路由侠 V0.5.5.0
6次软件大小:6.76 MB
更新日期:2024-10-14
豆包QQ相册留言 V2.0 绿色版
5次软件大小:384 KB
更新日期:2024-10-14
IE7pro(ie插件) V2.5.1 多国语言版
4次软件大小:4.74 MB
更新日期:2024-10-12
门路淘宝客辅助发货软件 V1.0 绿色版
4次软件大小:2.16 MB
更新日期:2024-10-13
服务器大师 V1.0 绿色版
4次软件大小:465 KB
更新日期:2024-10-10
Dns Jumper(DNS切换工具) V2.2 便携版
3次软件大小:624.84 MB
更新日期:2024-10-12
fs2you下载器 V2.2.0.1绿色便携版
3次软件大小:3.63 MB
更新日期:2024-10-08
MTools(快速配置IP和DNS) V1.0 绿色版
3次软件大小:22.27 KB
更新日期:2024-10-13
TCPView(查看端口和线程) V3.05 绿色中文版
3次软件大小:436.11 KB
更新日期:2024-10-07
商务密邮 V3.4 官方安装版
3次软件大小:40.86 MB
更新日期:2024-10-11
装机必备
最新软件
妇联通 V1.1.4 官方版
妇联通电脑版是一款通讯服务软件,将六级妇联组织层级扁平化,上情下达、下情上报尽快完成,可直接通过组织找到个人,红头文件随时查看,妇联通学习板块可以让大家一起进步。
大华e眼 V2.8.11.781
大华e眼它是款由大华旗下推出的远程视频监控系统。这款为电脑客户端,它能够远程控制监控器,具有强大的视频监控、录像回放、报警日志、报警日志等功能,可是实时掌握监控情况。 大华e眼主要功能 1、实时视频监控 2、录像回放 3、报警日志 4、电子地图 大华e
Csrt.dll免费版
Csrt.dll是电脑系统中一个非常重要的文件,许多的游戏或者软件运行都需要它的支持,如果没有这个文件可能会造成一些游戏或者软件运行不了。
迅雷助手 V11.10.05.1 绿色免费版
一键刷满下载被动经验,模拟官方签到。软件情况:软件来自网络,请下载者自行鉴定分析虚实!害怕勿下。
AccessToDB2(Access转DB2工具) V3.6 英文安装版
AccessToDB2是一款能够将access导出到db2的工具,其作用就相当于将access数据转换成db2数据,软件还可以用SQL语句查询数据,然后将数据直接转换成表,如果您会在每天固定的时间进行导出的话,还可以设置任务计划,实现自动操作。
虾传 V1.1
虾传是一款目前非常流行的音乐上传软件。该软件由虾米音乐网制作,为广大音乐爱好者提供便捷有效的音频上传操作,具有界面简洁,操作简单易懂的特点。
热门软件推荐
软件专题 更多+